



¿Cómo sabemos qué tan inteligente es una inteligencia artificial?
Con algunos "tests de inteligencia" especialmente preparados para la IA

Esta es una pregunta que debí hacerme antes; creo que lo di por sentado. Hablo todos los días con varias IA y nunca me he preguntado realmente qué tan inteligentes son, al igual que no lo haría si hablara con un humano. Pero en este caso, entenderlo me parece súper importante.

Como les había contado hace unos días, estoy probando Claude 3.5 Sonnet (spoiler alert: hasta ahora me ha sorprendido lo bueno que es). Sin embargo, no pude evitar sentirme un poco confundido cuando vi algunos benchmarks que acompañan su página de lanzamiento.
Según esto, Claude 3.5 Sonnet es muy inteligente en relación a ciertos benchmark scores. Se ve genial, ¿no?
Y aquí vemos cómo el último modelo de Anthropic se compara con otros LLMs como Claude 3 Opus (también de Anthropic), GPT-4o de OpenAI, Gemini 1.5 Pro de Google y Lama-400b de Meta.
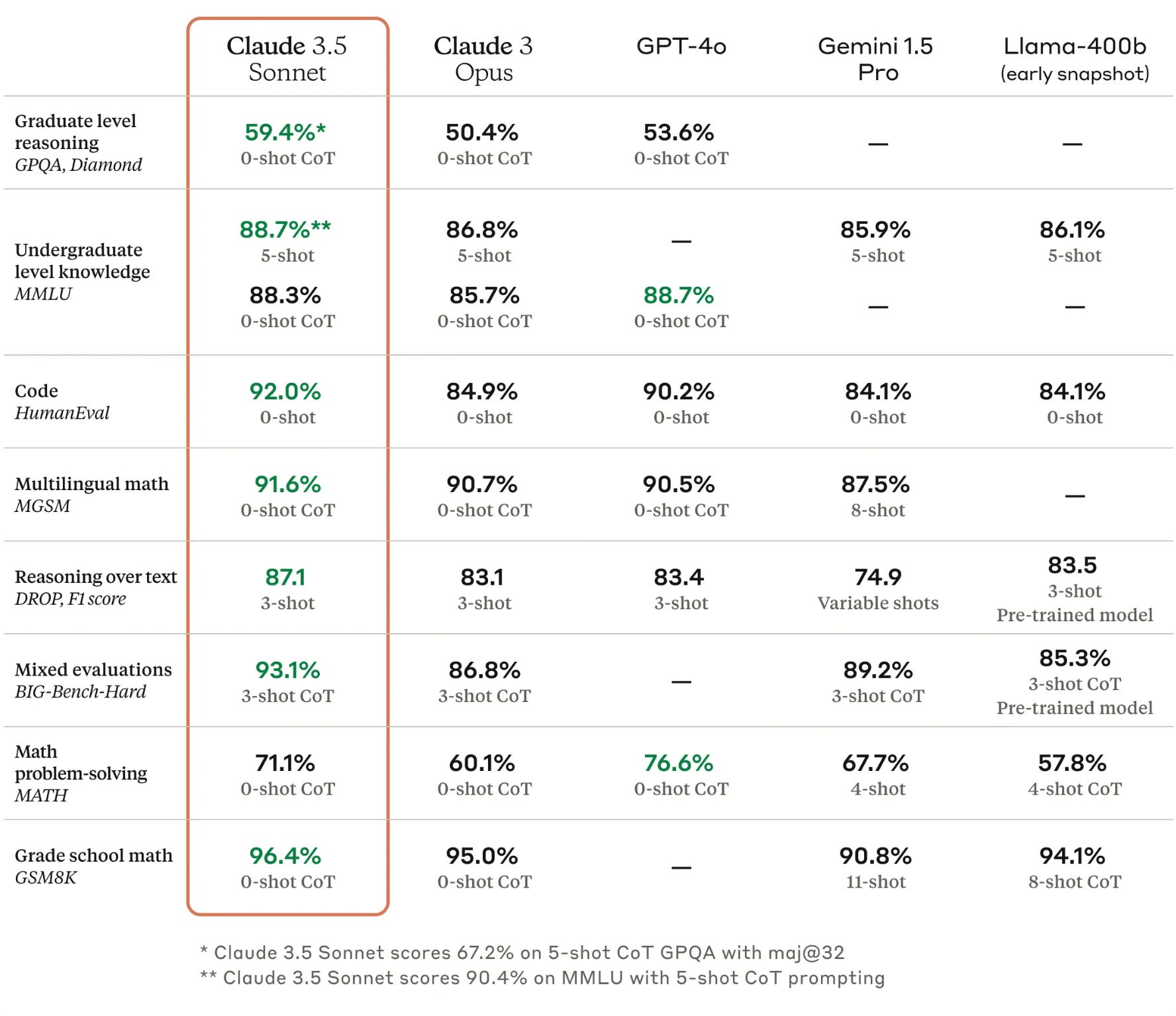
La primera vez que vi esos gráficos y tablas pensé: ¡Wow, esto debe ser increíblemente inteligente! Luego de 5 minutos me di cuenta de que realmente no sabía que eran GPQA, MMLU, BIG-Bench-Hard, y demás siglas raras. Me los imagino como tests de IQ para medir inteligencia artificial, y estoy seguro que no puedo ser el único que se haga esa pregunta. Con eso en mente me puse a investigar al respecto, así que ahora voy a tratar de hacer una breve explicación de cada uno.
Por cierto, vamos a mencionar mucho a los Large Language Models (LLMs), si no estás familiarizado con ellos, te recomiendo que le de una mirada al articulo que escribí sobre LLMs.
¿Como se mide la inteligencia?
Los humanos, hemos diseñado pruebas para evaluar modelos de lenguaje como ChatGPT, Claude, Lama, etc., y entender qué tan buenos son para responder cierto tipo de preguntas o realizar ciertas tareas. Esas pruebas son las que ves en la tabla cuando lees cosas como MGSM, HumanEval, GPQA, etc.
Además de esas siglas extrañas, en la tabla también leemos cosas como 5-shot, 0-shot CoT, 3-shot CoT, que planeo explicar en un futuro post. Basta saber que se refieren a la forma en que le “hacemos preguntas” al modelo durante la prueba.
Ahora sí, pasemos a ver cada una de estas “pruebas de inteligencia para IA”
GPQA Diamond
GPQA se define como “A Graduate-Level Google-Proof Q&A Benchmark”, es decir, una prueba de preguntas y respuestas de nivel de posgrado a prueba de google. Es un conjunto de 448 preguntas de opción multiple creadas por expertos en biología, física y química. Estas preguntas han sido creadas de manera que sean de muy alta calidad y extremadamente difíciles.
¿Pero qué tan difíciles pueden ser esas preguntas?
Pues tan difíciles que expertos que tienen o están por obtener un PhD en esas areas llegan a resolver solo el 65% de las preguntas. Tan difíciles que las personas no expertas sólo pudieron obtener 34% de precisión a pesar de haberse tomado su tiempo ¡y tener permitido acceder a Internet!
De esas 448 preguntas, existen 198 que son las más difíciles de contestar si no se tiene un profundo conocimiento en esos temas. A esas 198 se les conoce como GPQA Diamond.
MMLU
MMLU son las siglas de Massive Multitask Language Understanding (Comprensión masiva de lenguaje multitarea). Esta prueba trata de medir la capacidad de multitasking de un LLM, para eso toma 57 tareas incluyendo areas como matemática elemental, historia, sociología, etc.
La idea de esta prueba es que para pasarla, el modelo debe tener un conocimiento extenso del mundo y buena capacidad para resolver problemas.
Así, al tener preguntas en 57 areas del conocimiento, podemos saber cómo le va al LLM en cada una de ellas.
Se estima que un humano resuelva estas pruebas en un rango de precisión desde 34.5% cuando se aplica a personas no especializadas, hasta un 89.8% cuando se aplica a expertos.
Las 57 areas de MMLU
Me imagino que tendrás curiosidad sobre que temas se tocan en esta prueba, aquí puedes ver todas las 57 areas:
Abstract Algebra, Anatomy, Astronomy, Business Ethics, Clinical Knowledge, College Biology, College Chemistry, College Computer Science, College Mathematics, College Medicine, College Physics, Computer Security, Conceptual Physics, Econometrics, Electrical Engineering, Elementary Mathematics, Formal Logic, Global Facts, High School Biology, High School Chemistry, High School Computer Science, High School European History, High School Geography, High School Gov’t and Politics, High School Macroeconomics, High School Mathematics, High School Microeconomics, High School Physics, High School Psychology, High School Statistics, High School, US History, High School World History, Human Aging, Human Sexuality, International Law, Jurisprudence, Logical Fallacies, Machine Learning, Management, Marketing, Medical Genetics, Miscellaneous, Moral Disputes, Moral Scenarios, Nutrition, Philosophy, Prehistory, Professional Accounting, Professional Law, Professional Medicine, Professional Psychology, Public Relations, Security Studies, Sociology, US Foreign Policy, Virology, World Religions
HumanEval
Esta prueba intenta medir la capacidad de un LLM de crear código en un lenguaje de programación a partir de lenguaje humano. Otra cosa interesante es que no está delimitado a un solo idioma o lenguaje de programación sino que se prueba en 23 idiomas y 12 lenguajes de programación.
Hace unos días escribí sobre cómo los LLMs responden a diferentes idiomas, vale la pena darle una mirada.
¿Cómo funciona?
Según entiendo, se crea un prompt en inglés, que luego es traducido a los otros idiomas usando IA, luego se presenta el prompt en cada idioma al LLM para que genere código en diferentes lenguajes de programación y se mide la calidad del código generado.
Idiomas y lenguajes de programación
Aquí la lista de idiomas: Arabic, Hebrew, Vietnamese, Indonesian, Malay, Tagalog, English, Dutch, German, Afrikaans, Portuguese, Spanish, French, Italian, Greek, Persian, Russian, Bulgarian, Chinese, Turkish, Estonian, Finnish y Hungarian.
Y de lenguajes de programación: Python, Java, Go, Kotlin, PHP, Ruby, Scala, JavaScript, C#, Perl, Swift y TypeScript.
MGSM
Esta prueba trata de entender qué tan bueno es un LLM en problemas de matemáticas de escuela primaria. Sí, de esos que hacen los niños. MGSM viene de Multilingual Grade School Math (Matemáticas Multilingües de Escuela Primaria).
Para hacer esta prueba se tienen 250 problemas que han sido traducidos de inglés a 10 idiomas diferentes, estos problemas necesitan entre 2 y 8 pasos para ser resueltos. A diferencia de HumanEval, estas traducciones fueron hechas por traductores humanos nativos sin asistencia de IA.
Multilingüe (traducido por humanos)
Aquí los idiomas a los que se tradujeron las preguntas: Bengali (BN), Chinese (ZH), French (FR), German (DE), Japanese (JA), Russian (RU), Spanish (ES), Swahili (SW), Telugu (TE), y Thai (TH).
DROP
Drop es una prueba de compresión de lectura, pero no de lecturas complejas sino de párrafos. Así, DROP significa Discrete Reasoning Over the content of Paragraphs (razonamiento discreto sobre el contenido de párrafos).
Es un conjunto de más de 96,000 preguntas creadas via crowdsourcing a partir de un conjunto de textos que se obtuvieron de Wikipedia. Un punto que me pareció interesante es que algunas de las preguntas incluyen operaciones matemáticas con los datos presentes en el texto.
En el momento en que apareció, en 2019, los modelos tenían una precisión de 32.7% mientras que los humanos llegan a 96%. A la fecha los LLM han mejorado mucho pero aun no llegan al nivel humano.
Son sólo párrafos… en inglés
Además, ten en cuenta que se trata de comprensión de lectura de solo párrafos, y que aun falta mucho para que estos modelos tengan un entendimiento profundo de textos más complejos.
Además estos párrafos están sólo en inglés.
BIG-Bench-Hard
Esta es una prueba es interesante, se trata de pedirle al modelo de lenguaje que realize tareas para las cuales sabemos que no es realmente bueno, o al menos sabemos que no es mejor que los humanos (aún).
Esta prueba viene de la prueba BIG- bench (Beyond the Imitation Game benchmark) que consiste en 204 tareas que creemos que están más allá de las capacidades actuales de los modelos de lenguaje. De esas 204 tareas se seleccionaron las más difíciles, es decir, a la que los modelos se les hacían más complicadas, y ese subconjunto se llamó BIG-Bench-Hard, ago así como “las más difíciles del BIG-Bench”.
MATH
MATH es una base de datos con 12,500 problemas matemáticos de nivel de educación secundaria. Estas preguntas fueron tomadas de competencias de matemáticas por lo que no podemos decir que sean exactamente fáciles. Además están pensadas para resolverse en varios pasos.
Cuando se hizo la prueba con estas preguntas a modelos de lenguaje en el 2021, la precisión de las respuestas estuvo entre 3% y 6.9% (nada impresionante si eres un alumno se secundaria, pero bastante bueno para una máquina que acaba de aprender a hablar inglés). Estos modelos llegaron incluso a una precisión del 15% en las preguntas de menor dificultad e incluso cuando se equivocaban llegaron a generar soluciones paso a paso que eran coherentes (aunque erradas).
Se hizo la misma evaluación con humanos y según las pruebas un estudiante promedio de doctorado en ciencias de la computación a quien no le gustaba especialmente la matemática obtuvo 40% mientras que un campeón en las olimpiadas de matemática obtuvo 90%.
GSM8K
Lanzada el 2021, esta base de datos contiene 8,500 preguntas de matemática de secundaria, su nombre viene de Grade School Math 8K.
Estas preguntas pensadas también para evaluar a los modelos de lenguaje en este tipo de problemas. Las preguntas han sido seleccionadas especialmente para tener una alta diversidad lingüística. Esta base de datos de preguntas, como casi siempre pasa está en inglés.
¡Esas fueron varias pruebas!
Ahora que hemos explorado algunos benchmarks y tests de inteligencia para la Inteligencia Artificial, podemos entender mejor cómo se evalúa la capacidad de estos modelos.
Algo que me llamó la atención fue la simplicidad de algunas pruebas, o mejor dicho, lo simples que serían para un humano (adulto) realizarlas. El hecho de que estos tests evalúen la comprensión de lectura de un solo párrafo y matemáticas de primaria claramente nos da una idea de la capacidad de estos modelos. Aunque son muy articulados y pueden dar la impresión de no tener fallas, podría ser que no estén resolviendo algunos problemas de matemáticas o comprensión lectora al nivel de un niño de 10 años.
Además, es crucial tener en cuenta que muchos de estos tests se realizan en inglés. Esto significa que no podemos asumir que estos LLMs serán igual de precisos en otros idiomas.
Suficiente por hoy! Nos vemos pronto.
G